Stop fixing the wrong problem – Tylenol won’t help with that cough!
Most teams struggle with removing operational friction because they concentrate on surface-level reactionary fixes (usually bandied as tech debt removal) instead of addressing the fundamental causes of inefficiency.
This is like using Tylenol for a bad cough – you might feel better in the short term, but ultimately the cough doesn’t go away. Tylenol is not a panacea; it works for mild pain but doesn’t work for coughs, malaria, or constipation. Similarly, the blanket ‘tech debt‘ appellation is too fuzzy to generate permanent repair strategies.
This post proposes a systems-based model for diagnosing, detecting, and fixing the fundamental issues that plague engineering teams. It is a distillation of lessons acquired from identifying and implementing high-leverage strategic remedies across multiple products; it lets you know what to use: Tylenol for headaches, laxatives for constipation, and anti-malarial tablets for malaria.
The Software Factory Model
Picture an assembly line in a car manufacturing plant; the multi-stage transformation starts with raw materials and ends with delivering a new car. Successive stages bring the car closer to its final form by consuming the output of earlier stages. This interlinkage means undiscovered flaws grow into monstrosities later on – a misplaced screw can ruin a brand new car and necessitate massive expensive recalls.
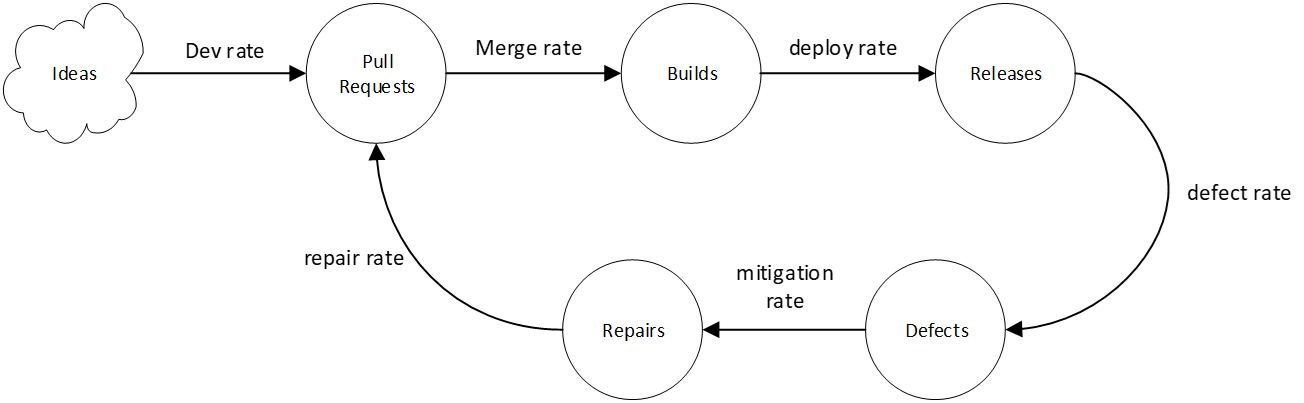
The software delivery pipeline similarly starts with requirements; these requirements are transformed into Pull requests (PRs), PRs are merged into builds, builds ship in releases and releases deliver value to customers. Like the misplaced car screw, an uncaught bug can quickly ruin a new feature. However, instead of massive recalls, most defects are fixed by shipping even more software (e.g. patches, upgrades, etc.).
A manufacturing process with a high defect rate will produce many defective products. Similarly, a high-defect software delivery pipeline will generate a lot of reactive fires in the form of bugs, outages, and customer pain.
Using the various production stages described above, we can set up a closed-loop systems-based model of software development as shown below:
Don’t miss the next post!
Subscribe to get regular posts on leadership methodologies for high-impact outcomes.
How I used this model to recover from reactive fires
No one expected usage to surpass 2-year growth projections within 2 quarters; the astronomical pandemic-fueled growth trapped everyone for a wild ride. Code, systems, and processes all broke under the unrelenting pressure of orders-of-magnitude growth.
Every weak link was ruthlessly exposed and laid bare for all to see. There were constant late-night alerts; customers would threaten to escalate up the chain, partners would ask for guarantees, unstated expectations would be forced on the plate, and surprises would pop out at random times and random periods: it was pure chaos.
The neverending deluge of outages wore out the team and the fix was to shore up the over-stretched team. I got hired and got handed a team of new hires as part of the drive to stem the tide. Read more about how I rapidly onboarded the team.
As a new manager in the org, I had one goal: permanently putting out the reactive fires. Systems thinking helped me identify the intervention points. After studying the model, the biggest challenges popped out:
- High defect rate: Pretty much every deployment caused an outage
- Low deploy rate: It was difficult to deploy builds: we sometimes went days without releasing
- Low mitigation rates: The group had grown apathetic to the deluge of incidents and was barely able to stay afloat
The org simply could not get code out without generating extra outages. I had two options for my new team:
| Option | First-order consequences | Second-order consequences |
|---|---|---|
| Feature development | Intuitive – the expectation was to start and quickly ship features. Low buy-in barrier: No need to convince the org. | Shipping more features without fixing the high defect rate fuels the raging fires of reactivity into a conflagration. That 2nd-order outcome of more outages eliminates all the euphoria of the short-term wins. |
| Systemic fixes | Non-intuitive – why focus on ‘tedious‘ systemic work instead of ‘shiny new’ features? High buy-in barrier: Convincing the org about the tradeoffs: limited short-term wins, potential morale impact, and the true cost of toil. | Systemic fixes eliminate toil permanently enabling the team to boost development velocity. Achieves the desired outcome of “Happy customers + Happy developers“; a predictable cadence of high-value delivery with minimal developer drudgery. |
I proposed a multi-quarter engineering strategy pivot that showed how the org could emerge from the morass of toil. The proposal advocated for eliminating outage-generating factories in our current stack and measured the expected increases in saved developer days. For example, we could free up three developers for new feature work by fully consolidating on one compute platform instead of two.
This clarity helped with achieving buy-in and we got some aircover to go explore the non-intuitive approach. I split my team into three workstreams tasked with each pillar and we got to work.
The team went from guaranteed late-night calls to having weeks free of any outage. Automated and reliable deploys also freed up the team from having to babysit builds and releases. Well-rested and less-distracted devs, in turn, could focus on driving more permanent fixes; the flywheel spun faster.
Conclusion
Modeling the software delivery pipeline as a system helped to identify high-leverage problems, predict 2nd-order effects, and implement the right strategy. The versatility of the model also explains why some teams never break free of reactive toil – they’re focused on the wrong problems.
Systems thinking is a powerful leadership tool for effective outcomes. It enables you to reason about and predict the future consequences of “seemingly obvious” decisions.
I hope you can leverage the model to identify high-leverage interventions for your team.
Don’t miss the next post!
Subscribe to get regular posts on leadership methodologies for high-impact outcomes.
Discover more from CodeKraft
Subscribe to get the latest posts sent to your email.

Your post on taking a systemic view of the software pipeline is incredibly insightful! I really appreciate how you broke down the complexities of the software development process into interconnected components. As someone in an offshore software development company, I can see how this perspective helps identify bottlenecks and optimize the overall workflow. https://techstackdigital.com/
LikeLike