A tale of two teams
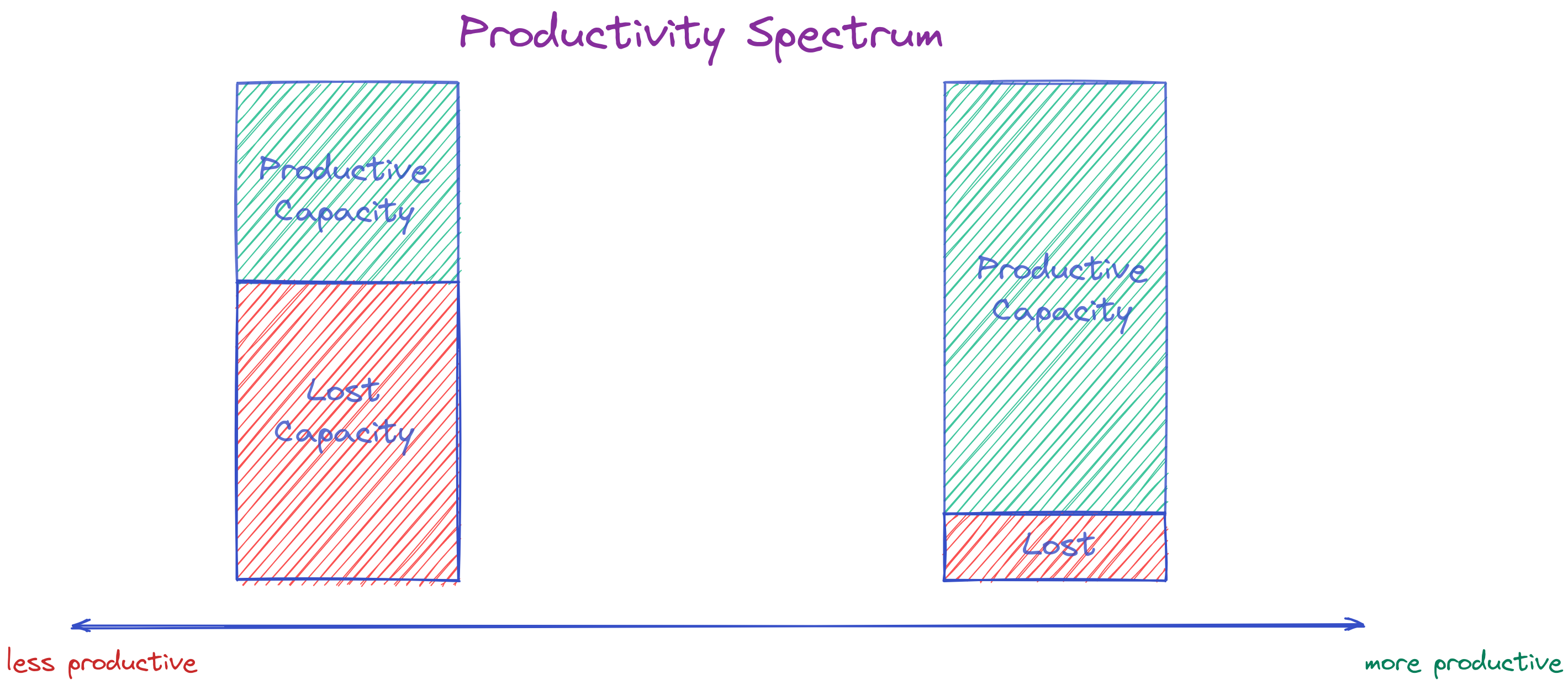
The productivity gradient between my best and worst teams was like day and night.
On the worst team, experienced engineers with decades of experience struggled to get any productive work done. Minor changes required wading through a tar pit of obstacles, mistakes occurred round the clock, and it was a miracle when things worked.
Conversely, on the best team, early-in-career engineers safely rearchitected significant parts of the system. Significant changes were a breeze, mistakes were rare, and it was a surprise when things broke.
Inefficient teams expend a lot of energy papering over various systemic flaws. These reactionary fires deplete productive capacity; imprisoning such teams in a vicious cycle of prolonged delivery timelines, tooling woes, and endless fire-fighting.
Optimizing team productivity
Physicists seek to minimize the coefficient of friction in their bid to achieve zero-friction ideals. Similarly, the ideal software delivery pipeline aims to reduce friction during the transformation of ideas into high-value features. Proper engineering systems and processes (ESPs) are the lubricants that minimize frictional losses due to undesirable surprises.
Surprises always require reactive funding; the team must divert critical resources towards fixing disruptive discoveries, thus reducing efficiency and effectiveness.

Multipliers (aka ESPs) reduce the chances of a chaos-driven cycle by revealing defects early, minimizing capacity losses to reactive fires, and empowering engineers with the right tools.
What are these multipliers that can make or mar a team’s productivity?
Don’t miss the next post!
Subscribe to get regular posts on leadership methodologies for high-impact outcomes.
Multipliers for Engineering teams
1. Observability
You can’t fix what you do not know.
Observability covers the spectrum of logging, metrics, distributed tracing, telemetry, alerting, etc. (the whole nine yards). Excellent monitoring reveals hidden flaws, cuts detection times, and simplifies customer experiment validation. Poor observability correlates linearly with high-defect rates, extended outage recovery times, and missed customer expectations. Having zero telemetry in production is like driving blindfolded.
2. Development loop
The code-build-test-debug (CBTD) loop is a good proxy for developer productivity. Let’s compare the average CBTD distributions for two hypothetical teams as shown below:
| Team A | Team B | |
|---|---|---|
| Code | 30 minutes | 30 minutes |
| Build | 10 minutes | 1 minute |
| Test | 10 minutes | 1 minute |
| Debug | 10 minutes | 1 minute |
| Total | 1 hour | 33 minutes |
There is a significant 27-minute delta between both teams. This difference grows with team size; for a 30-person team, the daily validation cost is 13.5 hours! Can you now see how a smaller team can out-execute a larger team?
Estimate your team’s CBTD; what does that number tell you?
3. Test Stability
Flaky tests erode trust and breed learned helplessness. Over time, the tests fall into disrepair; no one knows the validated scenarios and why tests pass or fail. This resulting practice thereafter is to rerun the tests until they succeed. This run-and-pray strategy thwarts all forms of confidence in the finished product; it is flawed on multiple counts:
- Inefficient allocation of resources to babysit unreliable tests
- Lack of trustworthy signals from the test system
- Lingering opacity into quality
4. Release Agility
An unpredictable value delivery system leads to erratic schedules; it becomes impossible to plan releases since the team manually shepherds features through dizzying contours. Conversely, a reliable automated delivery system ensures that features ship on time and with high quality.
5. Documentation
Teams that rely on a few sages are bottlenecked on those same sages. A hallmark of a fragile team is the extreme reliance on a few chosen guardians; these custodians know the arcane intricacies of the system; however, their invaluable knowledge is locked up in their memories. Consequently, piled-up tasks overwhelm the custodians, the entire team is one or two resignations away from implosion, and team efficiency suffers due to hero-worship tendencies.
Documenting tribal knowledge increases team efficiency, breeds a scalable knowledge-sharing culture, and boosts team resiliency. It is usually the first step towards a culture of reading, writing, and asynchronous collaboration. A great example is Architectural Decision Records.
Read more on documentation as a high leverage activity for teams.
6. Automated operations
It is a colossal waste of precious resources to have developers manually do what computers can do. Systems requiring manual intervention drain morale, have linearly-growing toil, and are susceptible to mistakes. The inevitable errors, when they occur, fuel the fire of chaos; further depleting the available capacity. Having untested automation is even worse, due to the false assurance. You do not want to be testing out the most critical parts and solutions amid a disaster; this is not a drill, folks.
7. Experimentation
There is nothing so useless as doing efficiently that which should not be done at all
Peter Drucker
Experimentation validates assumptions by closing the feedback loop and proving/disproving hypotheses; this tight learning loop steers development towards customer wants. Experimentation systems smoothen releases by simplifying segmented rollouts (e.g., location, persona, or device); they also simplify stress-testing assumptions about customer behavior by enabling A/B trials and targeted releases to select cohorts.
A culture of experimentation increases the probability of achieving product-market fit.
8. Hiring + Onboarding
How you hire and onboard new folks determine your team’s long-term productivity and culture. When done poorly (i.e., without careful planning, structure, and process), these two factors disrupt high-performing teams and introduce lingering dysfunction. Sample metrics to use:
- Hiring: The offer-to-acceptance ratio
- Onboarding: How long it takes new hires to become proficient
Read more in my article on hiring and team jell.
9. Infrastructure as code (IAC)
Multiple sources of truth lead to config drift which invariably spawns bugs, confuses developers, and replicates unnecessary work. Combining IAC with automation unlocks higher productivity benefits; IAC guarantees one source of truth, and automation ensures repairs consume a stable config. The antithesis is to rely on ad-hoc changes; over time, these untracked changes morph into an unmanageable source of pain.
Striking a balance between feature delivery and engineering investments
Technical leaders balance the opposing tensions of customer and engineer happiness. Over-indexing on one category occurs at the detriment of the other, e.g., you can ship many features by overworking the team (happy customers, unhappy engineers) or work on shiny new fads and ignore all customer asks (unhappy customers, happy engineers).

Use Multipliers to drive Engineering Strategy
The key is to achieve the optimal balance – the fitting selection of multipliers is dependent on multiple factors like product maturity stage, team productivity needs, and business roadmap. A team might have excellent test coverage but suffer from incessant outages due to poor observability; another team might have excellent observability but struggle to release features to customers.
Investments in these multipliers should be proportional to the needs of the business – think of them as an investment portfolio that needs to be rebalanced periodically. You can use the table below to determine what multipliers to prioritize at any stage.
| Multiplier | Indicators / Metrics |
|---|---|
| Observability | Time To detect, Time to repair, defect rates |
| Dev loop | Development rate |
| Test Stability | Defect rates, Merge rates, Pass rates |
| Release Agility | Lead time, cycle time, deploy rates |
| Documentation | Lead time, blockers |
| Automation | Time to mitigate, Time to repair |
| Experimentation | Experimentation rate |
| Hiring + Onboarding | Development rate, Time to first PR |
| Infra as code | Time to mitigate, lead time |
Quick Exercise: Where does your team stand?
On a scale of 1 to 10, rate your current team across these 9 multipliers. What stands out?
Caution: Efficiency is not effectiveness
Having the right systems and processes doesn’t mean you are doing the right things; it just means the team is super-efficient. Two of the failed products I worked on had excellent engineering systems; one struggled to achieve market traction, while the second was slow to react to the competition.
Effectiveness is about fusing technical strategy and business vision.
Conclusion: Curating the optimal multiplier portfolio
Funding these multipliers should be proportional to the needs of the business – like an investment portfolio that needs to be rebalanced periodically. The leader should evaluate their current state and future vision – just as you monitor your investments.
These multipliers (e.g., observability, release agility, etc.) apply across engineering organizations. Over time, teams that invest in boosting the right capabilities at the right time will get more done with less. Teams that neglect these capabilities will eventually get bogged down – they’ll get less done with more.
Check out how to use Systems thinking to boost your team’s efficiency.
Thanks to Ayuba, Matias Lespiau, and Diego Ballona for reviewing drafts of this post.
Don’t miss the next post!
Subscribe to get regular posts on leadership methodologies for high-impact outcomes.
Discover more from CodeKraft
Subscribe to get the latest posts sent to your email.
