All systems break at scale
Scaling challenges fall into four categories – compute, memory, storage, and network. Many tried-and-tested techniques exist for the first three categories – e.g., load-balancing and stateless services for compute bottlenecks, caching and memory-efficient algorithms for memory constraints, and sharding and replication strategies for storage limitations.
The rarity of scaling challenges involving network constraints is a double-edged sword – these problems only occur under extraordinary circumstances; however, when they emerge, they are quite difficult to understand, troubleshoot, and fix.
One of my favorite technical projects involved overcoming a network constraint. The virtual machines (VMs) hosting the core services kept exhausting available ports. Once all ports were used up, which happened more frequently than we wanted, new connections would fail, tanking our availability and reliability.
As with most tricky problems, the real work involved problem framing, research, and hypothesis validation; once we had the fix, the implementation was relatively straightforward. Read on to learn how we overcame this issue and opened up opportunities to reduce costs by a third.
Contributing Factors to the constraint
A unique combination of issues led to this challenge. The first issue was a lack of cloud-native architecture; the service preceded the cloud-computing era and worked well at a small scale – think file shares for intra-company networks. With the advent of Azure, the on-prem topology was lifted and shifted to the cloud to establish a foothold. This migration introduced some challenges, but these were manageable as the service grew organically.
The second complicating factor was the reliance on Azure classic compute – a deprecated version of Azure; Azure classic compute preceded the widespread availability of orchestrators like Kubernetes or ServiceFabric. This constraint blocked the adoption of newer systems because there was no interoperability across both versions; you either chose ARM (the newer version) or classic; you could not mix both. Furthermore, it was challenging to get support; most times, the advice was ‘move’ to the newer ARM platform.
The pandemic changed everything – the rapid spurt in usage bared all flaws; it became a challenge to maintain the availability and reliability SLAs; everyone was working long hours and running helter-skelter to keep things going smoothly. Failure was not an option – the services powered mission-critical needs across sectors like healthcare, education, and energy.
The three challenges:
- The lack of cloud-native architecture
- The deprecated underlying compute platform
- The mission-critical nature of the services necessitated hard uptime guarantees
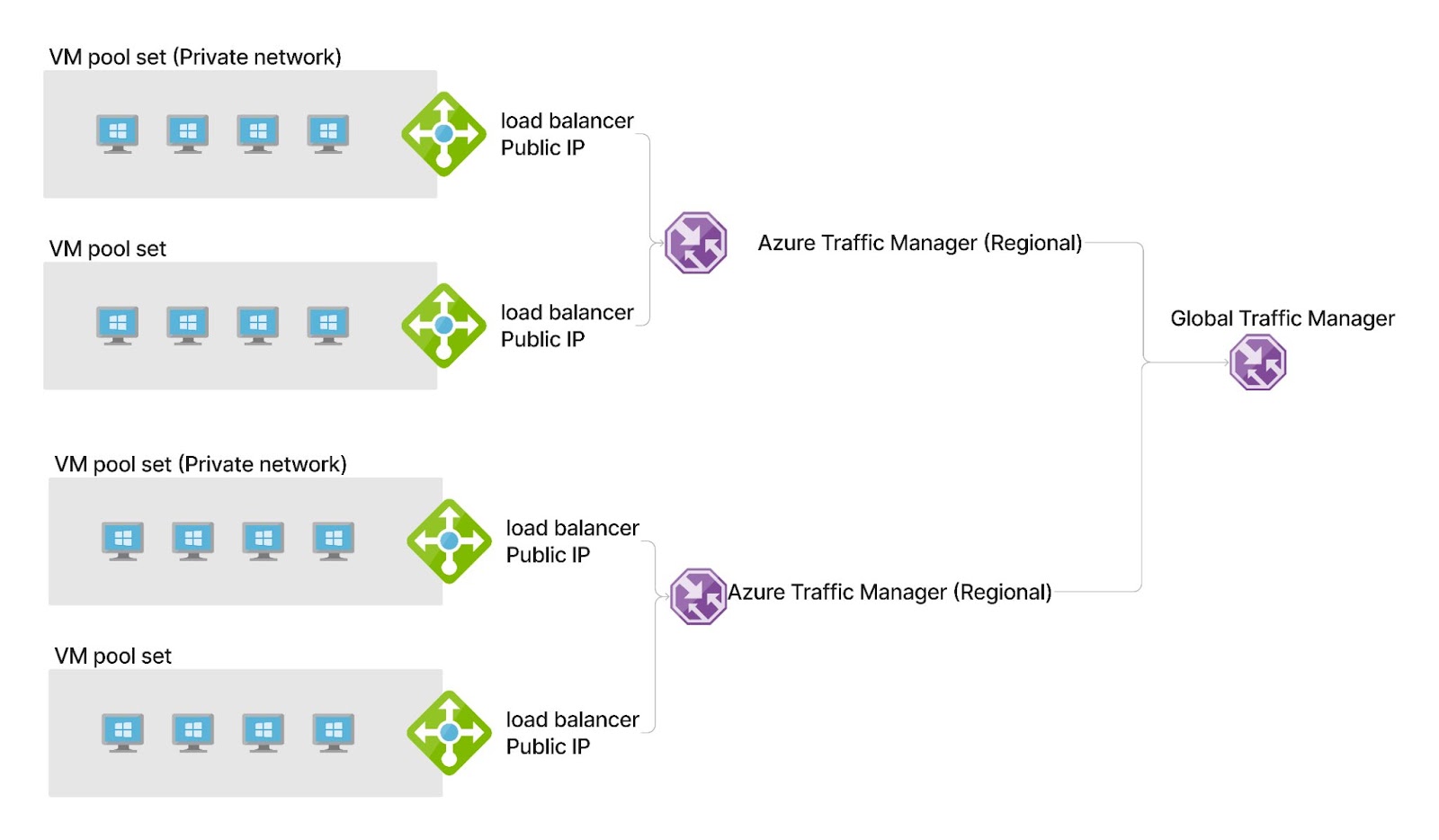
High-level Service Topology
Each service had its dedicated pool of VMs; a VM pool is a collection of VMs on the same virtual network that can be managed as a single unit; this model simplified operational needs like deployment, scaling, and maintenance.
An internal load balancer (ILB) serves as the public interface for a pool, and all machines on the internal network route requests through the ILB. Due to the scale, a service might need many pools, and these disparate pools were linked via nested Azure Traffic Manager (ATM) instances (ATM is a DNS-based load balancer).
A high-level overview of the service topology:
The Symptom: Availability and Reliability plunges
The first challenge was identifying the cause of the reliability dips; the existing monitoring systems all looked good, yet we knew something was wrong because of the deluge of unhappy customer reports. Read this to learn how to reliably plug observability disconnects.
Log analysis revealed many timed-out requests, so we added more instrumentation across all dimensions, and sure enough, the root cause popped up: the compute hosts were running out of ports!
During the peaks of traffic bursts, the VMs maxed out on all outgoing connections and exhausted all ports. Now that we knew the root cause, the next question was why the machines ran out of ports, which required understanding how VM pools were set up.
Understanding the VM pool topology
The challenge occurred when VMs made outbound calls, e.g., sending back a response or calling an external service like Redis. All outgoing connections from VMs in the pool had to be funneled through the ILB. VMs were assigned prefixed port ranges via Port Address Translation (PAT); the ports uniquely identify the originating VM and ensure responses got routed to the correct VM in the private network.
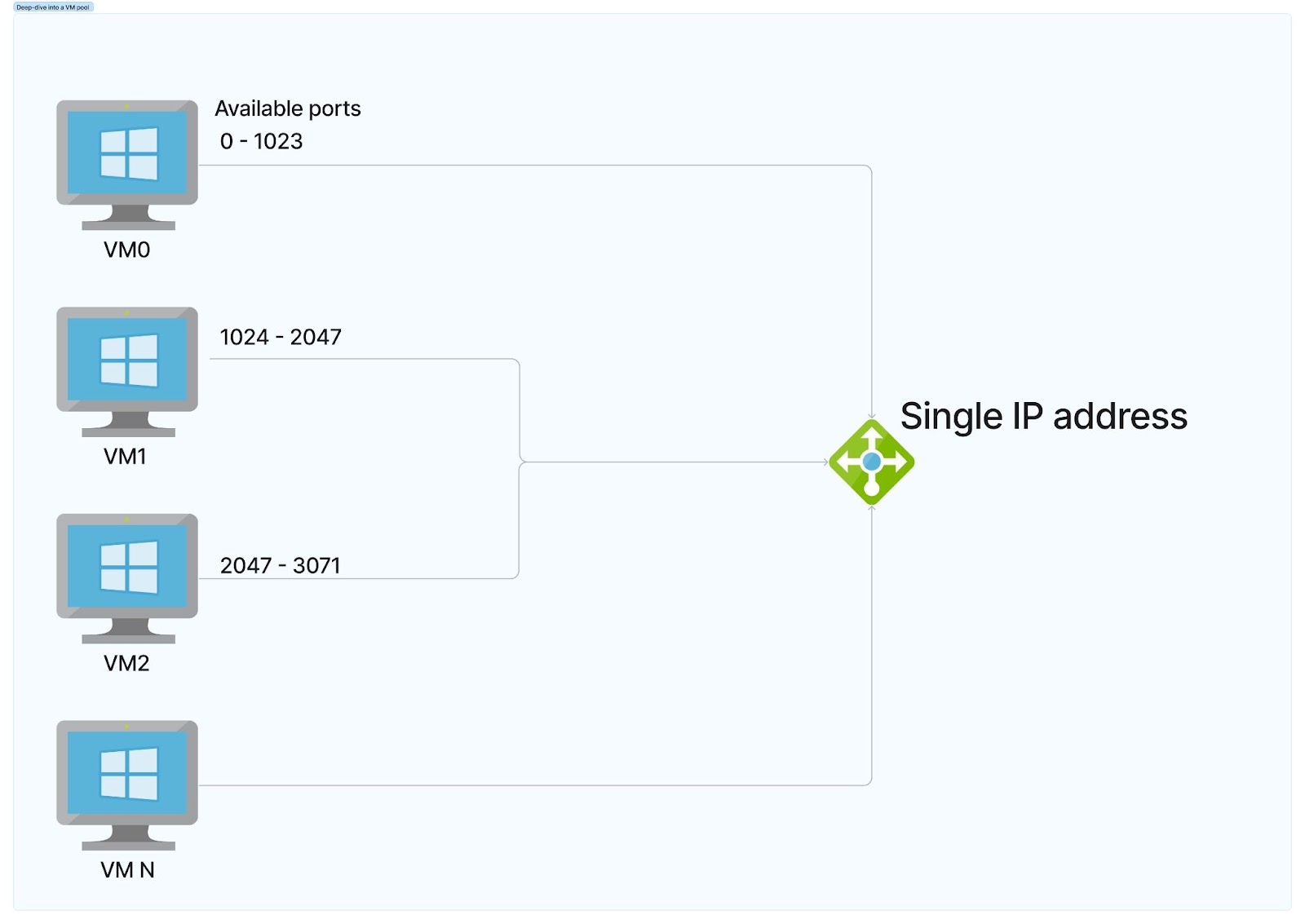
Available ports vs. Pool Size
The mechanism for allocating ports was not configurable and depended on the number of VMs in the pool; more VMs meant fewer ports available per VM.
| Pool size (Count of VMs in the pool) | Count of ports per VM |
| 1 – 50 | 1024 |
| 51 – 100 | 512 |
| 101 – 200 | 256 |
| 201 – 400 | 128 |
| 401 – 800 | 64 |
| 801 – 1000 | 32 |
Communicating over the Internet
Private IP addresses are not accessible over the public Internet and vice-versa. When a computer on an internal network needs to reach a public destination, network address translation (NAT) transforms its internal IP into an externally-accessible IP address. A good example is devices in a private home network communicating through the router (a public IP address). This helps with conserving the limited pool of public IP addresses.
There are three traditional ways of addressing the NAT problem:
- Static NAT: Assigns public IP addresses to each VM in the private network. This can be very expensive since the pool of IP addresses is limited.
- Dynamic NAT: Assigns a collection of IP addresses to the private network; outgoing connections are multiplexed through this pool of IP addresses. It needs upstream planning and network forecasting to match demand to provisioned capacity.
- Port Address Translation (PAT): Maps multiple private IP addresses to one public IP address by leveraging different port numbers.
As you might expect, the Azure Classic compute used PAT. And the ILB, configured with only one publicly available virtual IP address, was the bottleneck.
How do ports get exhausted in PAT?
A 5-tuple uniquely identifies every network connection: source IP address, source port, destination IP address, destination port, and transport protocol. Usually, these five dimensions introduce adequate variability, but this is not the case for the ILB scenario. Imagine a VM opening multiple connections to the same endpoint; the 5-tuple collapses into a monuple since the only variable is the port number.
| Source IP | Source Port | Destination IP | Destination Port | Protocol |
|---|---|---|---|---|
| Load balancer IP | VM1-Port-1 | 141.81.109.20 | 443 | TCP |
| Load balancer IP | VM1-Port-2 | 141.81.109.20 | 443 | TCP |
| Load balancer IP | … | 141.81.109.20 | 443 | TCP |
| Load balancer IP | VM1-Port-1023 | 141.81.109.20 | 443 | TCP |
Port exhaustion occurs when a VM exhausts its allocation of ports; at this point, outbound calls fail until ports free up. Low-latency calls did not hog ports – 50-millisecond calls to Redis freed up ports rapidly; the problem arose while retrieving large files from slower data stores; these long-running connections during traffic bursts quickly exhausted the 1024 ports available per VM.
Don’t miss the next post!
Subscribe to get regular posts on leadership methodologies for high-impact outcomes.
The quick bandaid to get ports and its drawbacks
The bandaid approach was to throw money at the problem—overprovisioning compute resources to guarantee an abundance of network ports. Each additional VM pool meant about 50k more ports, so it was a case of matching predicted traffic levels to available VM supply within budgetary limits.
This approach provided temporary relief, a quick way to meet uptime requirements for customer needs, and reduced the on-call burden on the already overstretched team. However, overprovisioning had the following drawbacks:
- Not failsafe: Unforeseen events would trigger traffic spurts that exceeded our forecasted capacity peaks. Everyone monitored capacity allocations with bated breath since any burst could topple service reliability. Also, there were times when we simply could not buy more VMs; for example, during DC outages, there was simply no available VMs to buy.
- Maintenance Toil: The laborious rollout process took a lot of engineering resources – it involved forecasting expected usage, requisitioning for VM pools, and finally deploying these VMs and adding them to the ATMs. After deployment, the constant need to monitor capacity and adjust resources took its toll on team productivity – it sapped morale like water drains through a basket.
- Too expensive: we sometimes had 3X the CPU capacity needed to ensure we had enough ports. Most VMs ran at ~20% CPU usage, and we had to accept this inefficiency because right-sizing the VM fleet would have cut the number of available ports.
This temporary mitigation did not give us peace of mind, and we could not afford to keep spending money. We needed a sustainable long-term solution that was failsafe, toil-free, and affordable.
The journey toward a permanent fix
This section describes how we went through three approaches before arriving at a 4th approach that solved the problem.
Migrating to Azure Kubernetes Service (AKS)
Moving off the deprecated Azure classic compute to Azure Kubernetes would have solved the problem by enabling the adoption of newer Azure offerings (e.g., Azure NAT gateway offered millions of ports via software defined networking).
The downside was the required upfront cost; conservative estimates put the migration around three developer years. We would have to migrate compute platforms, redefine our dev loop, and overhaul the entire engineering stack (think releases, observability, documentation, etc.). Furthermore, migrating such a large-scale service was fraught with risks associated with unknown unknowns.
Instance Level Public IP addresses (ILPIP)
This approach involved assigning every VM in the private network an IP address – leading to a 64x bump in available ports per machine (65k ports/VM vs. 1024). Also, since ILPIPs were available in Azure classic, this approach did not require a migration off classic compute.
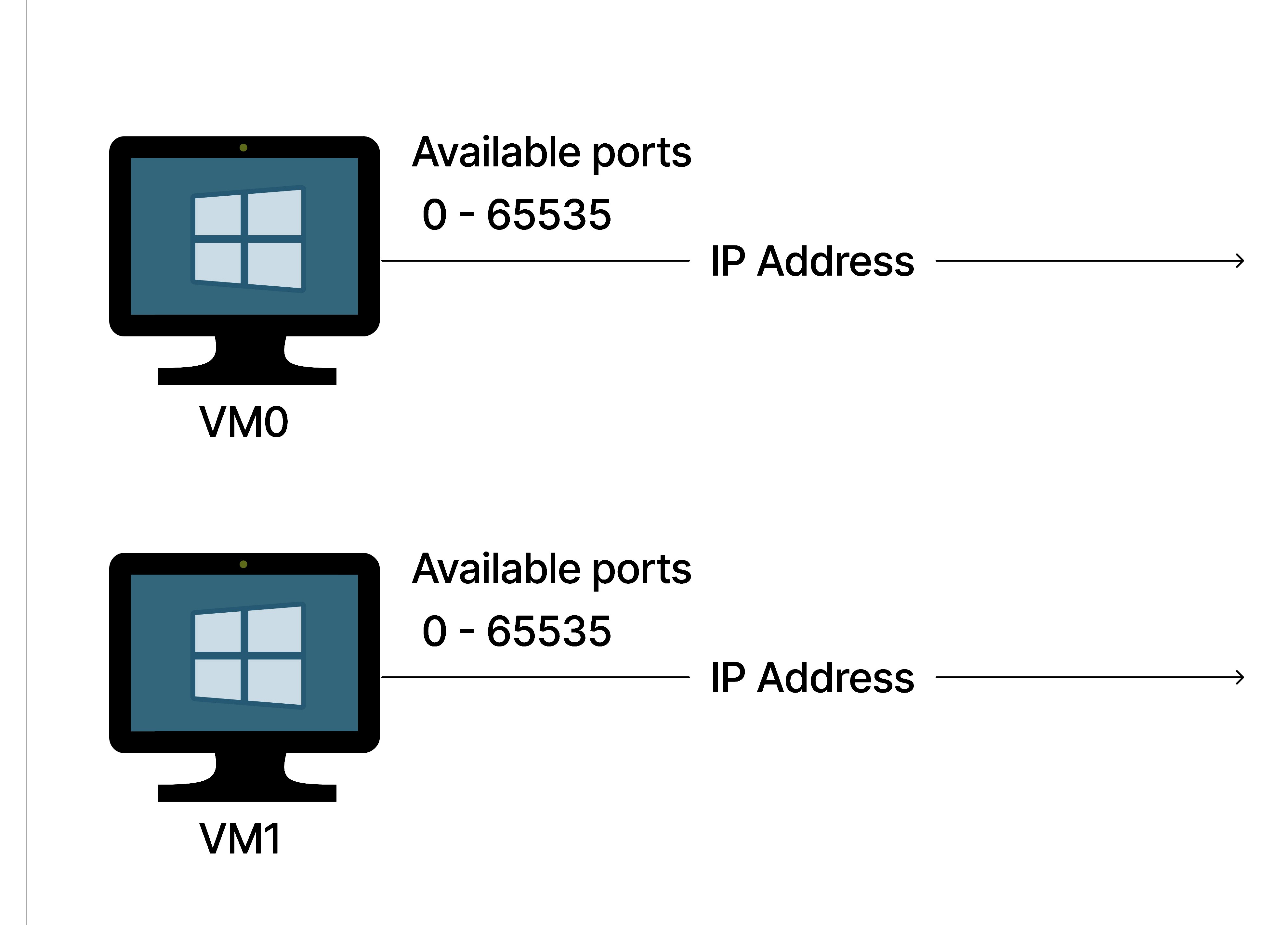
Significant challenges with ILPIP blocked an adoption – we would take on new compliance and security validation since the VMs would bypass Azure’s default network policies. We also could not get enough ILPIPs; even if we did, the operational burden of managing each VM as a unit instead of managing the higher-level VM pool abstraction meant undesirable extra work; it would have necessitated rethinking our entire service topology. The costs far outweighed the benefits.
Chunking files into smaller sizes
The main reason for port exhaustion was file retrieval operations from slower storage services. This approach explored chunking up files into smaller sizes to guarantee those retrieval operations were completed within a time limit. The second-order effect was that ports would be freed up and available for newer operations.
Splitting up files required redefining the file format in a backward-compatible manner; that was a Gordian knot, especially for a service with millions of active users and a wide variety of client versions. The client-driven upgrades also meant that a format rollout would have taken years to reach critical mass. The complexity, cost, and risks meant this approach was also a no-go.
Using Multiple Virtual IPs at the Load balancer
This fix targeted the ILB, the bottleneck that necessitated more ports during traffic spikes. Modeling proved that we only needed a 3–4x multiple of the available ports for the worst-case scenario; thus, by allocating more virtual IPs (VIPs) to the ILB, we could easily overcome the reliability challenge without revamping our whole architecture.
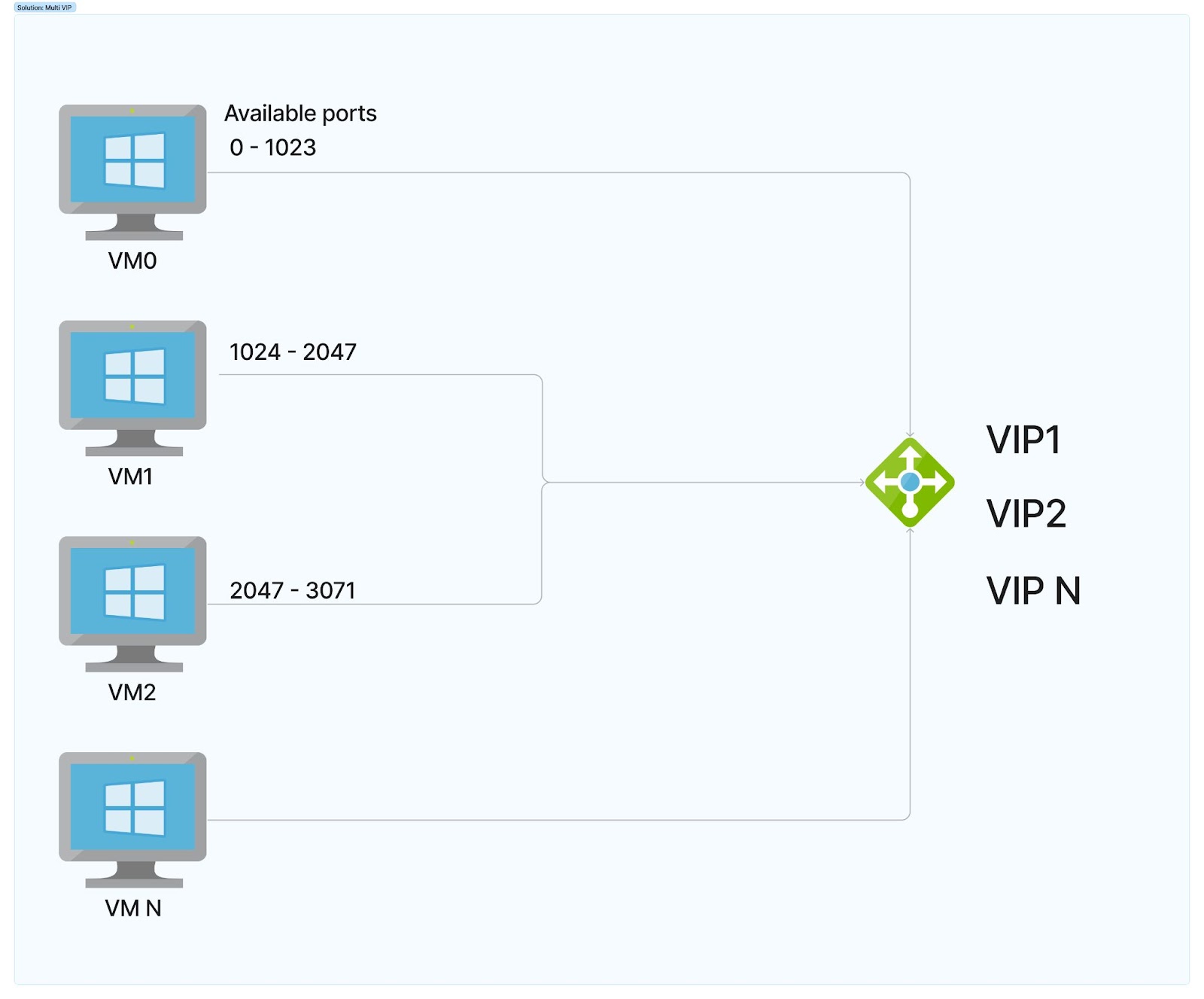
Adding more VIPs to the ILB meant more multiplexed connections. For example, the table below shows how having two IPs at the ILB doubles the available ports for each VM from 1024 to 2048.
| Source IP | Source Port | Destination IP | Destination Port | Protocol |
|---|---|---|---|---|
| Load balancer IP1 | VM1-Port-1 | 141.81.109.20 | 443 | TCP |
| Load balancer IP1 | VM1-Port-2 | 141.81.109.20 | 443 | TCP |
| Load balancer IP1 | … | 141.81.109.20 | 443 | TCP |
| Load balancer IP1 | VM1-Port-1023 | 141.81.109.20 | 443 | TCP |
| Load balancer IP2 | VM1-Port-1 | 141.81.109.20 | 443 | TCP |
| Load balancer IP2 | VM1-Port-2 | 141.81.109.20 | 443 | TCP |
| Load balancer IP2 | … | 141.81.109.20 | 443 | TCP |
| Load balancer IP2 | VM1-Port-1023 | 141.81.109.20 | 443 | TCP |
Since this sounded too good to be true, we stressed-test the limits before investing in the engineering fixes. A VM was set up with two VIPs; a script created multiple simultaneous calls while we monitored used ports.
The test was successful – the VM established 2048 outgoing concurrent connections (1024 ports per VIP). This gave us the confidence to go ahead with the targeted engineering changes, set up a safe deployment plan, and then evangelize the fix to partner teams.
Conclusion
Surmounting this rare networking constraint was a tough challenge; the esoteric problem required understanding how deprecated technologies work under the covers and then pushing the limits by engaging experts from various teams. This remains one of my favorite technical projects because it offered a broad spectrum of obstacles
- Discovery: it required a lot of exploration to identify the root cause
- Research: extensive research to understand possible fixes
- Iterations: Multiple solutions and engagements with experts to ideate on fixes
- Validation and Verification: Trusting and then verifying that the multi-VIP approach was viable
This stability eliminated the manual toil associated with capacity planning, and we achieved our reliability goals. In addition, this also opened up the pathway to significantly reduce compute spend. The team could now start optimizing and right-sizing the fleet of machines without worrying about port constraints.
I plan to write more about less common technical challenges I have encountered across multiple products – failing during cluster issues, surprise outages due to misconfigured systems, and rapidly deploying a new monitoring solution.
Don’t miss the next post!
Subscribe to get regular posts on leadership methodologies for high-impact outcomes.
Discover more from CodeKraft
Subscribe to get the latest posts sent to your email.
